Word Embedding, word2vec
머신러닝을 하기 위해서 자연어를 처리해야 하는데, word embedding은 초반에 이루어지는 작업 중 하나다. 모든 텍스트는 숫자로 표현해야하는데 특히 벡터로 바꾸는 모델을 word embedding model 이라고 한다. 그리고 임베딩 모델 중 가장 대표적인 모델은 word2vec 이다. 단어 임베딩 모델은 크게 두가지로 나뉘는데 frequency based embedding 과 prediction based vector 방식으로 나뉜다.
Frequency based embedding
문서에서 나오는 단어의 빈도수를 기반으로 임베딩을 하는 방식이다.
Count vector
문장의 수 D, 단어의 종류 (토큰)의 수 N 일 때, 행렬 $M_{D \times N}$ 으로 빈도수를 나타낼 수 있다.
TF-IDF vector
Count vector와 다르게 문서의 개수를 기준으로 빈도수를 계산한다.
Co-Occurrence vector
유사한 단어가 함께 발생한다 라는 의미로 관련성이 높은 단어, 중요한 단어를 기준으로 임베딩하는 방식이다. 단어 사이의 의미를 파악하고 재사용할 수 있는 장점이 있지만 유사하다는 것 이외의 단어의 성격등을 파악하기 힘들고 차원의 저주에 걸릴 수 있는 단점이 있다.
Prediction based vector
단어를 벡터화 시킬 때 확률을 이용하며 단어의 유사성, 의미와 같은 점에서 뛰어난 성능을 보여준다.
Distributed representation
높은 차원과 sparsity의 문제를 해결하기 위해서 더 낮고 dense한 분산 표현을 얻기 위한 방법이다. 분산표상 은 비슷한 의미를 갖고 있는 단어는 비슷한 문맥에 등장하는 경향이 있다 라는 가정으로 벡터들 간의 유사성이 측정 가능하다.
NNLM (Neural Network Language Model)
자연어에는 문법과 규칙이 존재하지만 예외 사항과 시제의 변화, 중의성과 같은 문제를 모두 명세하여 사용하는 것은 불가능에 가깝다. 그래서 가장 좋은 것은 모델이 실제 사용되는 자연어 데이터를 학습하는 것이 좋다라는 것이 NNLM의 motivation이다.
언어 모델링은 이전 단어들의 조합으로 다음 순서에 올 단어를 확률적으로 예측하는 것을 통칭한다.
We want to play soccer in _
4-gram 모델이라면 play soccer in만 사용하여 예측한다.
대표적인 것이 n-gram 모델인데, 이는 예측하려고 하는 단어 바로 앞의 n-1개의 단어만을 참고하고 나머지는 무시하는 것을 말한다. 그리고 가지고 있는 자연어 데이터에서 play soccer in 을 갖고 있는 문장을 가져와 다음에 올 단어를 확률적으로 계산한다.
가지고 있는 자연어 데이터 에서 뽑아오는 확률이기 때문에 데이터가 없다면 확률은 0이 되어 예측이 올바르게 되지 않을 가능성이 있다는 단점이 있다.
하지만 NNLM은 다르다.
우리 도시는 주민들의 건강을 위한 프로그램을 장려한다
우리 도시는 주민들의 건강을 위한 프로그램을 촉진한다
위의 두 문장은 비슷한 뜻이다. 만약 우리가 장려한다 와 촉진한다 의 유사성을 알고 있다면 두번째 문장을 태어나서 처음 보더라도 첫번째 문장과 비슷하게 이해할 것이다. 이 방식이 NNLM의 원리이다. n-gram은 두번째 문장을 처음 본다면 확률이 0이기 때문에 예측을 전혀하지 못할 것이다. NNLM도 n-gram처럼 앞의 특정 n개의 단어를 참고한다. 이 단어들을 one-hot-encoding 하여 layer 통과시키면 $n \times m$ 의 행렬이 나오게 되는데 이를 임베딩 벡터라고 한다.
word2vec
word2vec 은 단어의 유사도를 고려하는 NNLM을 더 개선시킨 모델이다. 단어를 벡터화 시키고 단어는 연관성을 갖는다는 것을 생각해보면 단어 끼리 연산이 가능하다는 뜻인데, 아래 사이트에서 경험해볼 수 있다.
이 사이트는 word2vec을 테스트해볼 수 있다. 단어끼리 연산이 가능한데, 음악-비트+붓 = 미술 과 같은 결과를 얻을 수 있다. 이는 모델이 음악과 미술의 연관성을 알고 있다는 뜻이다. One-hot encoding은 해당되는 값만 1이고 나머지는 0인 희소벡터 (sparse)라고 한다. 이렇게 하면 단어간의 유사도를 알기 힘들기 때문에 단어의 의미를 다차원 공간에 포함하는 분산 표현을 사용한다.
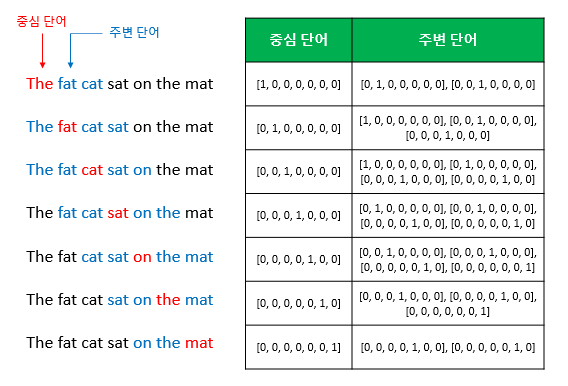
위 그림과 같이 기준 단어를 중심으로 주변에 있는 단어를 정해놓는다. 주변단어로 정해두는 크기를 윈도우 라고한다.
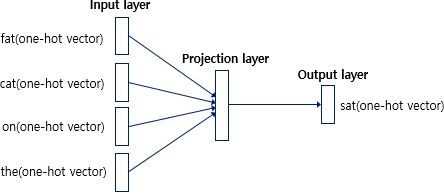
위 방식은 word2vec의 CBOW 방식이다. 왼쪽에 있는 단어들은 네트워크의 input layer이다. 여기에는 예측하고자하는 주변단어가 들어간다. 오른쪽은 네트워크의 output layer이고, 여기에는 예측하고자 하는 중심단어가 들어간다.
위 방식과 반대인 skip-gram 은 input과 output이 반대이다. 중심 단어로 부터 주변단어를 예측한다.