RNN은 문단, 자연어 처리 , 이미지 caption, 번역 등등 sequence data (or 시계열 data)에서 사용되는 모델이다. 본론으로 들어가기 전에 어떤 식으로 사용되는지 알아보고 설명을 이어나가는게 이해하는 데에 더 효과적일 것 같다.
어떻게 사용 되는가?

one to one은 RNN이라기 보다 그냥 일반적인 NN 모델(neural network)이다. one to many의 예시에는 Image Caption이 있다. 하나의 이미지를 보고 여러 단어를 통해 문장을 만들어내는 과정이다. many to one의 예시에는 문장의 성격을 알아내는 Sentiment Classification이 있다. 여러 단어의 문장을 보고 긍정, 부정 혹은 감정등을 유츄해낼 수 있다. many to many의 대표적인 예시에는 번역 및 연관어 검색이 있다.
어떻게 작동 되는가?
RNN의 핵심은 이전 입력값들을 기억하고 있어서 새로운 입력값이 영향을 받는 구조다. 우리는 문장을 이해할 때, 매번 단어 하나하나를 분류하고 해석한 뒤 문장을 이해하지 않는다. 먼저 읽었던 부분을 기억하고 있다면 다음에 나오는 부분을 읽을 때 영향을 끼친다. 이러한 기억은 RNN에서 hidden state로 불린다.
우리는 “나는 불행하게도 오늘 지갑을 잃어버렸기 때문에 정말 기분이 좋지 않다.”라는 문장을 읽을 때, “불행하게도”라는 부분만 읽고 나서도 벌써 부정적인 문장임을 무의식 중에 느끼고 읽는다.
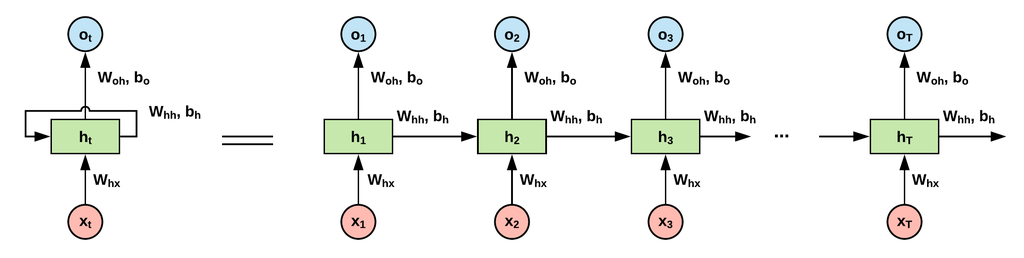
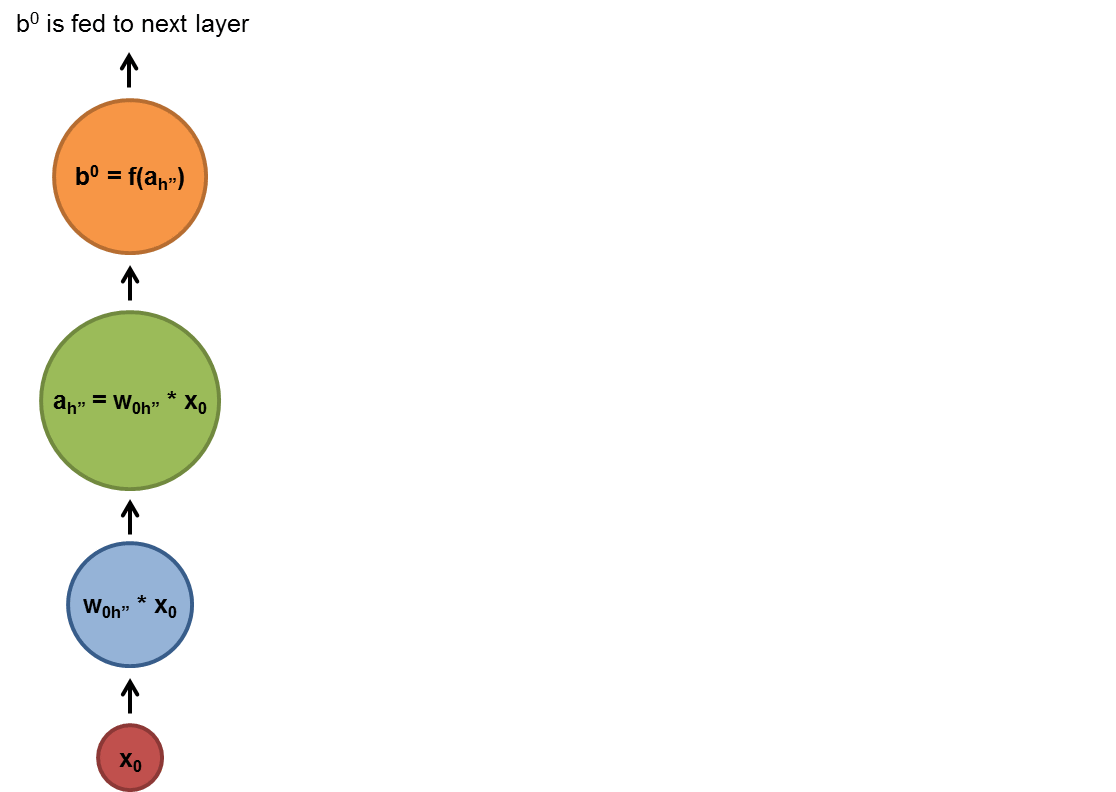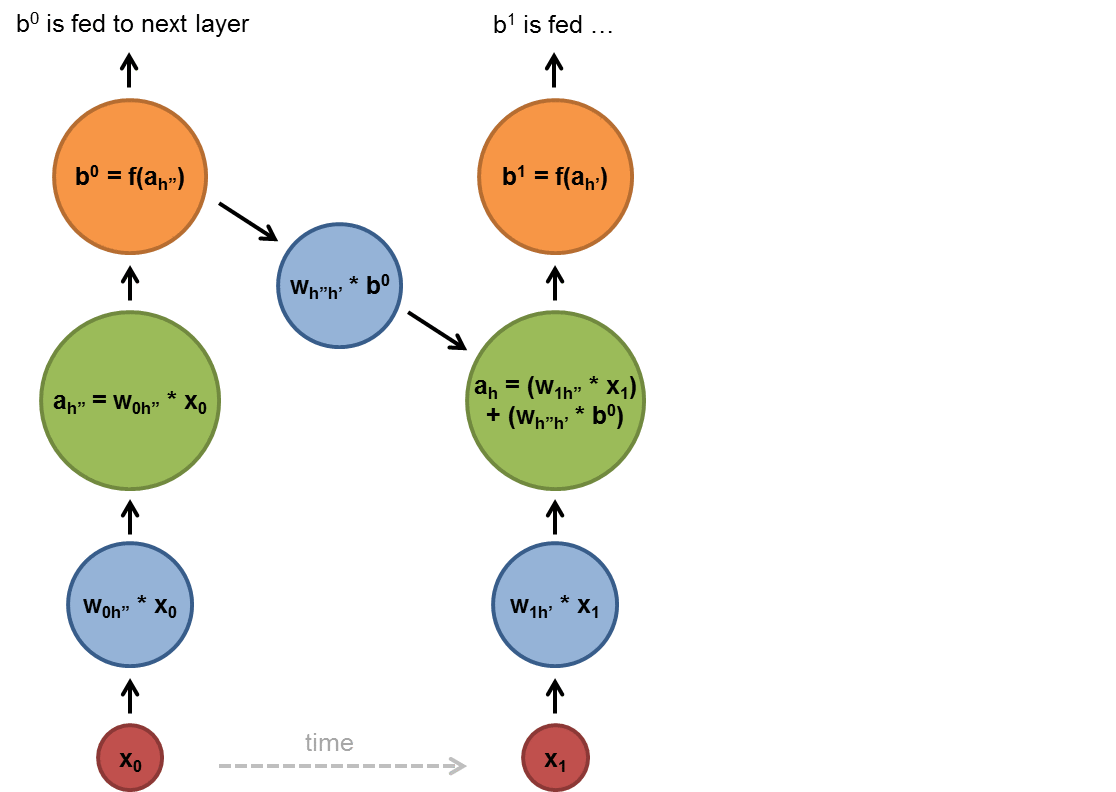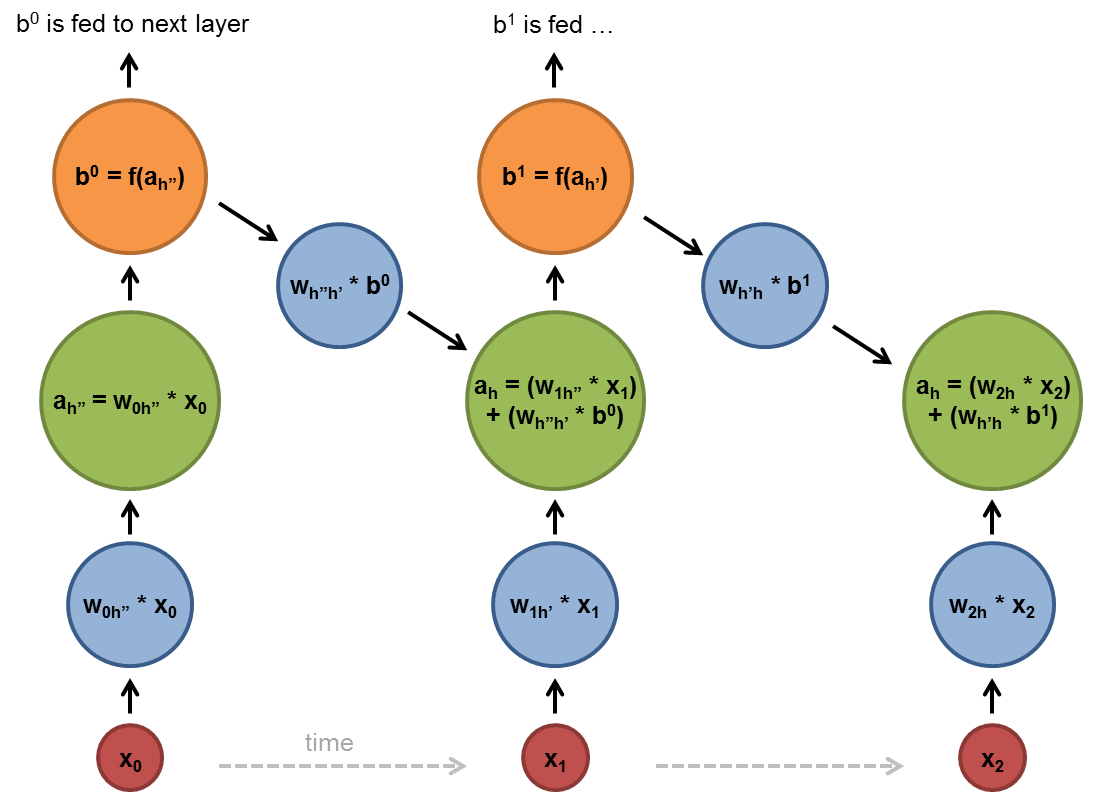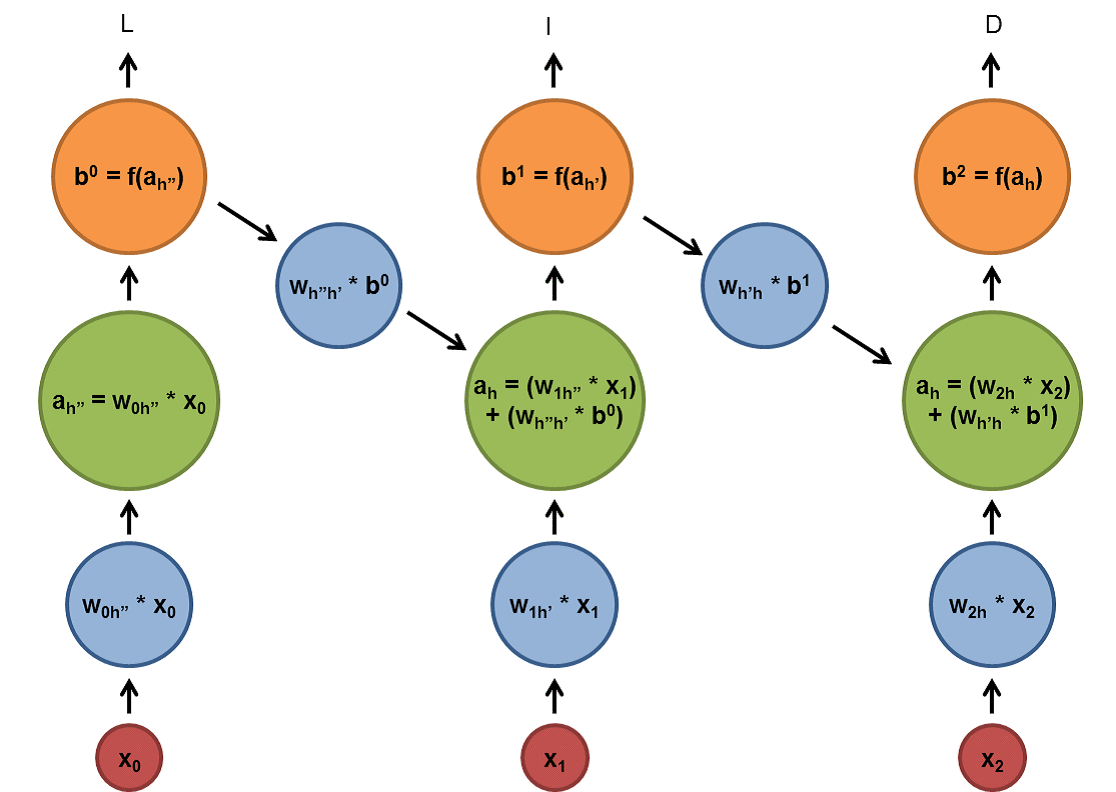
$h_t$는 시간이 t일 때, state를 의미한다. $W_{hh}$, $W_{xh}$, $W_{hy}$는 model의 파라미터이고, 모든 state를 반복하는 동안 모두 같은 파라미터 값을 사용한다. state($h_{t}$)는 다음과 같이 정의된다. (위 그림에서 $o_t$를 $y_t$로 생각하자)
활성함수로는 tanh가 사용되었다.
값이 층층이 쌓이는 네트워크 구조에서는 활성함수가 선형이 아닌 비선형 함수가 되어야 한다. 선형함수가 세번 겹쳐져 있으면 그대로 선형함수이기 때문에 효과를 볼 수 없다. ( $f(x) = a*x$ 일 때, $f(f(f(x))) = a^3x$ )
그리고 $y_{t}$는 다음과 같이 정의된다.
$y_{t} = W_{hy}h_{t} + b_{y}$
$h_{t}$를 보면 값에 영향을 미치는 두가지의 값이 선형결합을 이루고 있음을 알 수 있다. 하나는 $x_{t} (input)$이고, 하나는 $h_{t-1} (state)$이다. 즉, 이전의 값이 새로운 값을 만드는데 영향을 주는 것을 알 수 있다.
잘 보면 우리가 일반적으로 사용하는 Neural Network와 RNN은 크게 다르지 않다는 것을 알 수 있다. 위 그림을 보면 하나의 network가 복사된 형태를 가지고 있다.
아래 gif그림은 RNN이 진행되는 과정이다.
구현 (Keras)
문자열 생성 (예측)
문자열을 예측하는 모델을 만들어보자. hihello라는 문자가 있다고 가정하자. input으로 hihell가 들어갈 것이고 output으로 ihello가 나오도록 학습시킬 것이다. RNN이라고 복잡하게 생각할 것 없다. 큰 틀에서 보면 (model 구성방식, 작동방식…) 다른 딥러닝과 크게 다르지 않다. input을 집어넣고 output이 나오도록 학습한 뒤 정확도를 보면 된다. 단지 하나의 layer 안에서 위에 있는 방식처럼 정보 하나하나가 차례대로 recurrent하게 작동 될 뿐이다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, TimeDistributed, Activation, SimpleRNN
import numpy as np
RNN layer는 SimpleRNN을 사용할 것이다. (LSTM을 많이 사용하지만 튜토리얼이기에 사용해보겠다.) 우선적으로 알아야할 내용은 input dimension, output dimension(hidden), sequence length이다.
input dimension
input으로 hihello중에서 한 단어씩 series로 들어가는데, one-hot encoding 형태로 들어갈 것이다.
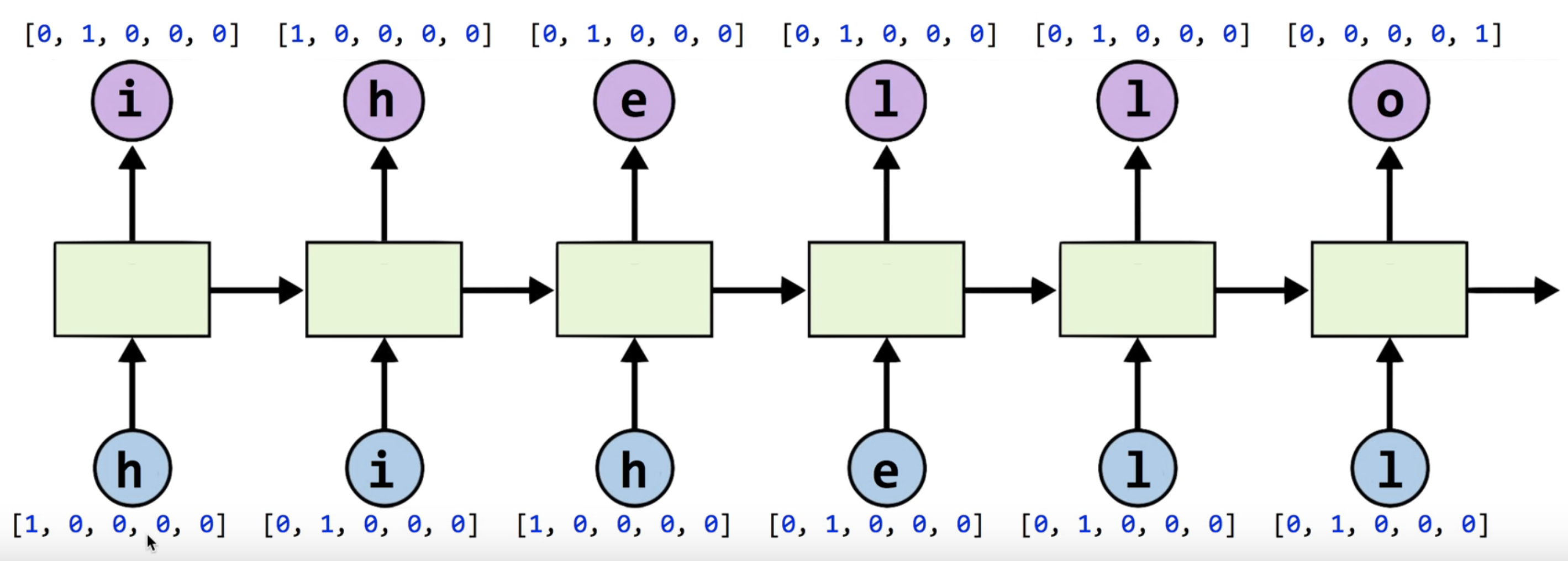
hihello의 문자종류는 총 5개 이므로, one-hot encoding을 거치면 단어 하나의 dimension은 5가 될 것이다.
output dimension
output dimension도 one-hot encoding을 거친 문자 중 하나가 될 것이므로 dimension은 5가 될 것이다.
sequence length
RNN의 가장 큰 장점은 input 데이터가 series로 들어간다는 것이다. 문자 하나가 들어가서 하나만을 예측하는 것이 아니고 여러개가 들어가서 여러개를 예측할 수 있다.(many to many) 이러한 경우 우리가 받는 데이터(input data)의 크기를 sequence length라고 한다. 이 예제의 input은 hihell이므로 6이 된다.
이 모든것을 다 숙지하고 있지 않더라도 keras는 간단하게 layer를 사용할 수 있도록 해준다. SimpleRNN layer에 다음과 같이 parameter를 넣으면 된다.
SimpleRNN(num_node, input_shape=(sequence_length, input_dimension), return_sequences=True)
layer에서 노드(neuron) 개수, sequence 크기와 dimension, return_sequences를 설정할 수 있다. return_sequences의 default 값은 false이고, false일 때는 마지막 hidden만 출력한다. true일 경우, sequence 전체를 3차원 shape으로 return한다. 우리는 sequence to sequence (many to many) 문제를 풀기 때문에 True로 설정하면 된다.
이제 training data 전처리를 진행해보자
sample = "hihello"
# unique chars of sample
char_set = list(set(sample))
# index of sample
char_dic = {w: i for i, w in enumerate(char_set)}
x = sample[:-2]
y = sample[2:]
print(x)
print(y)
print(char_dic)
hihel
hello
{'e': 0, 'i': 1, 'h': 2, 'o': 3, 'l': 4}
훈련시킬 데이터와 label 데이터를 만들었다. set함수를 사용해서 간단하게 unique characters를 뽑아냈고 labeling도 해주었다. 이제 labeling 된 숫자를 그대로 사용할 수 없으니 one-hot encoding을 해주어야한다.
one-hot encoding은 0을 [1, 0, 0, 0, 0], 1를 [0, 1, 0, 0, 0], 2를 [0, 0, 1, 0, 0], 3을 [0, 0, 0, 1, 0], 4를 [0, 0, 0, 0, 1]로 표현하는 방식이다. 이렇게 하는 이유는 머신러닝에서 데이터를 학습할 때, 벡터로 데이터를 나타내기 때문이다. 어렵지 않은 방식인데다가 성능도 꽤나 괜찮다. 하지만 단어 사이의 연관성을 전혀 알 수 없고(거리가 가깝고 먼 정도를 따질 수 없다) 단어군이 커지면 기하급수적으로 계산량이 늘어난다. 그래서 임베딩이라는 개념이 생겨난다.
하나하나 만들어 줄수도 있지만 함수를 통해서 간단하게 만들 수 있다.
from tensorflow.keras.utils import to_categorical
x_to_num = [char_dic[c] for c in x]
y_to_num = [char_dic[c] for c in y]
print('---------char2num----------')
print(x_to_num)
print(y_to_num)
data_dim = len(char_set)
num_classes = len(char_set)
x_hot = to_categorical(x_to_num, num_classes=num_classes)
y_hot = to_categorical(y_to_num, num_classes=num_classes)
x_hot = x_hot.reshape((-1, len(x_hot), data_dim))
y_hot = y_hot.reshape((-1, len(y_hot), data_dim))
print('---------num2hot----------')
print(x_hot)
print(y_hot)
---------char2num----------
[2, 1, 2, 0, 4]
[2, 0, 4, 4, 3]
---------num2hot----------
[[[0. 0. 1. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1.]]]
[[[0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 1. 0.]]]
이제 본격적으로 layer를 구성해보자. Keras는 Sequential이라는 함수를 통해 차곡차곡 layer를 쌓아가면 된다.
timesteps = len(x)
rnn =Sequential()
rnn.add(SimpleRNN(num_classes, input_shape=(timesteps, data_dim), return_sequences=True))
rnn.add(TimeDistributed(Dense(num_classes)))
rnn.add(Activation('softmax'))
rnn.summary()
rnn.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
rnn.fit(x_hot, y_hot, epochs=1000)
TimeDistributed는 일종의 wrapper다. Dense layer(일반적인 node를 가진 hidden layer)가 3차원 텐서를 받아들일 수 있도록 해주는 역할을 한다. SimpleRNN을 통과한 데이터는 3차원 형태일테니 말이다. Classification에 많이 쓰이는 activation function인 softmax를 마지막으로 사용하였다.
predictions = rnn.predict(x_hot, verbose=0)
for i, prediction in enumerate(predictions):
print(prediction)
x_index = np.argmax(x_hot[i], axis=1)
x_str = [char_set[j] for j in x_index]
print(x_index, ''.join(x_str))
index = np.argmax(prediction, axis=1)
result = [char_set[j] for j in index]
print(index, ''.join(result))
[[1.9736007e-02 1.9381046e-03 9.6048379e-01 8.0731796e-04 1.7034717e-02]
[9.6206737e-01 6.2139350e-04 2.7587399e-02 6.6434988e-04 9.0595111e-03]
[1.7527793e-02 9.0061396e-05 1.0543849e-02 7.3272001e-04 9.7110558e-01]
[6.5588410e-04 2.5094673e-04 5.2231411e-04 6.2390656e-04 9.9794692e-01]
[5.9827678e-05 1.7554006e-03 7.7487848e-04 9.9716187e-01 2.4808978e-04]]
[2 1 2 0 4] hihel
[2 0 4 4 3] hello
학습 후, prediction을 출력하고 예측 단어를 다시 decoding하면 원하는 답이 나오는 것을 볼 수 있다.
문제점
RNN은 장기 의존성(Long-Term Dependency)라는 문제점을 가지고 있다. 이 장기 의존성 문제를 간단한 예시로 알아보자. 먼저 두가지 정보의 위치가 가까운 경우를 살펴보자. “The boat is on the water.” 라는 문장을 학습시킨 후, “The boat is on the – .”라는 문장을 주면 network는 쉽게 빈칸에 water라는 단어를 넣을 수 있다. 이는 두 단어 정보의 위치가 가깝기 때문이다.
하지만 “The boat is on the water. A sailor is driving that.”라는 두 문장이 있다고 해보자. 우리는 boat와 sailor가 연관단어인 것을 알고 있지만, 두 단어의 gap이 크기 때문에 쉽게 예측하지 못한다.
LSTM으로 해결!
위에서는 SimpleRNN을 사용했지만 간단하게 LSTM을 사용하면 더 다양한 문제에서 높은 성능을 보여주는 layer를 구성할 수 있다.
자세한 작동방식은 다음 포스팅으로 이어나가겠다.