CGAN은 나온지 시간이 꽤 지난 GAN의 응용모델이지만 GAN을 이용한 연구에 많은 영감을 주고 있다. Vanilla GAN은 real 이미지를 주면 real 이미지와 비슷한 fake 이미지를 만들어 내지만, fake 이미지를 만들어 내는 과정을 관여할 수는 없다. MNIST 데이터를 예를 들어보자면 Vanilla GAN의 generator는 숫자를 무작위로 만들어낼 뿐이다. 하지만 CGAN은 숫자 1을 원하면 숫자 1을 뽑아낼 수 있다.
어떻게 작동되는가?
latent vector
generator에 들어가서 이미지를 만들어내기 전의 임의의 noise를 latent vector라고 칭한다. VAE와는 다르게 GAN은 latent vector가 존재하는 latent space의 확률분포를 정의하지 않는다. 즉, latent vector를 해석할 수 없다는 뜻이다. 해석할 수 없다는 뜻은 latent vector 중에 어떤 요소가 어떤 특징을 담당하고 있는지 알 수 없다는 뜻이다. 그래서 어떤 구분단위에 대한 것들을 labeling하고 함께 학습을 시키면 label(class)에 따라서 fake 이미지가 정리될 수 있다.
MNIST 데이터를 통해 쉽게 설명하자면, 0부터 9까지 가지고 있는 가장 쉬운 특징은 숫자 모양 그 자체일 것이다. 그 종류는 10종류이다. 이 10개의 class과 함께 학습을 시키는 것이다.
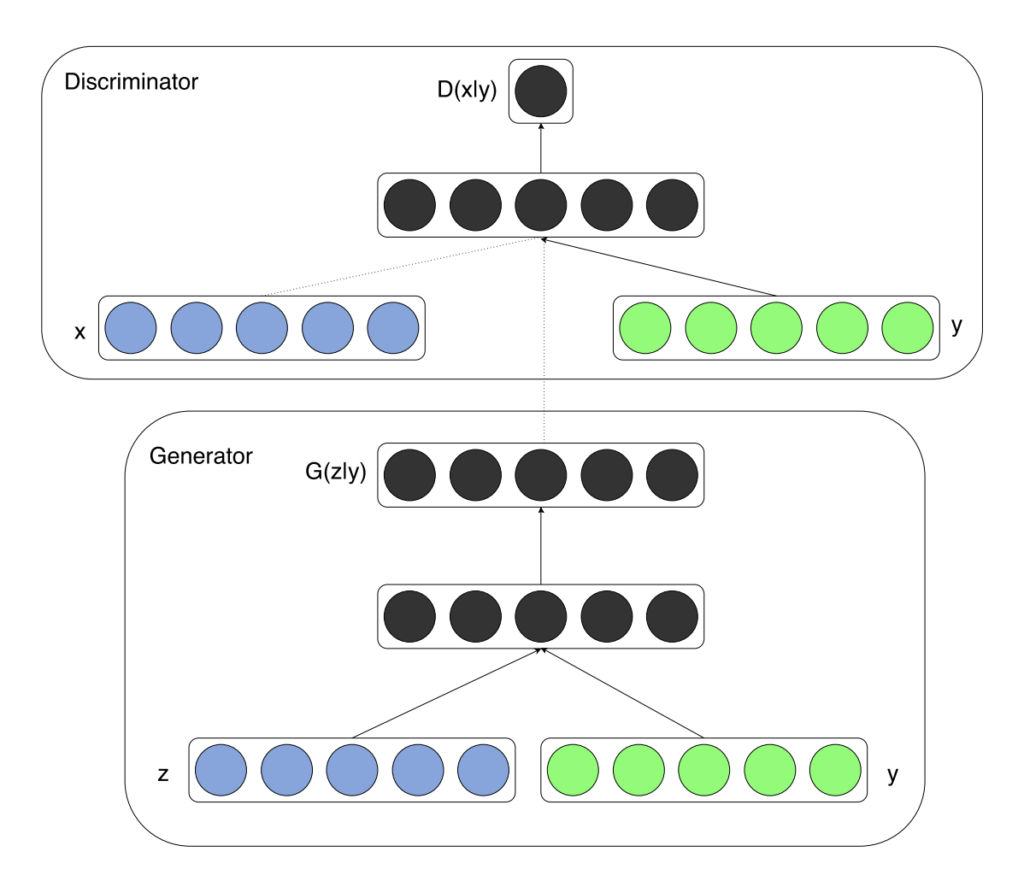
위에서 Discriminator의 x는 fake 이미지와 real 이미지가 combined 된 배열이다. y는 class이다. MNIST 데이터의 경우에는 0~9의 숫자가 될 것이다. (당연히 임베딩된 형태로 들어가야 한다) Generator의 z는 (우리가 알 수 없는)latent vector이고 y는 역시 class이다.
Adversarial Network를 조금더 자세히 보자.
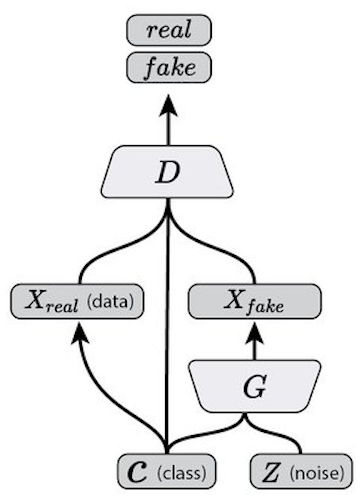
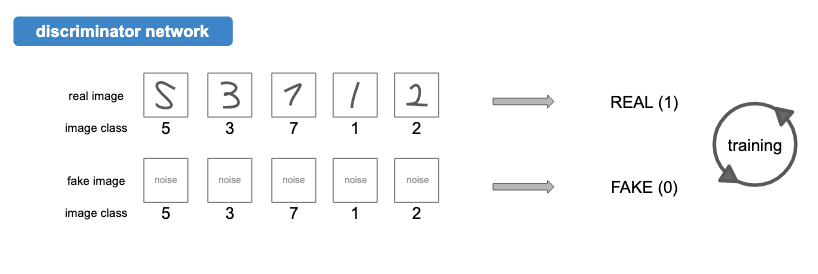
Discriminator는 [image, image_class]를 Input으로 받아서 real or fake를 output으로 내뱉는다. 다음과 같이 진짜와 가짜를 구별하는 능력을 학습할 것이다.
Generator는 [noise, image_class]를 Input으로 받아서 fake_image를 output으로 내뱉는다. 이 fake_image가 image_class와 함께 다시 discriminator를 통과하면 real로 판정받도록 adversarial network를 구성한다.
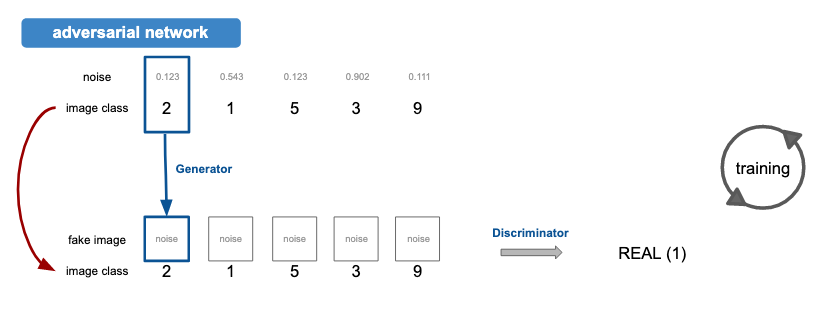
이렇게 되면 fake 이미지를 만들 때 noise 뿐만 아니라 image_class라는 변수도 고려해서 이미지를 생성하게 되고, real 이미지와 fake 이미지를 구별할 때도 image_class를 고려해서 판단하게 된다.
위 그림에서도 확인할 수 있듯이, G(z|y)는 특정 image class(y) 조건에서의 noise(z)로 만든 fake이미지 이고, D(x|y)는 특정 image class(y) 조건에서의 이미지(x)가 진짜인지 아닌지 판단하는 것이다. 다시 말해서 network는 y조건에 따라 분류되면서 training한다.
loss function
각 network(discriminator nets & adversial nets)의 output은 어차피 0~1 범위로 동일하므로 기본적인 binary_crossentropy를 사용하면 된다.
구현
MNIST 데이터를 통해 0~9까지 원하는 숫자를 뽑아내보자.
Generator
유의할 점은 앞서 얘기한 바와 같이 input이 2개(class가 추가된)로 들어간다는 것이다. Generator는 다음과 같이 만들 수 있다.
def create_generator(self):
G = Sequential()
G.add(Dense(256, input_dim=self.latent_dim))
G.add(LeakyReLU(alpha=0.2))
G.add(BatchNormalization(momentum=0.8))
G.add(Dense(512))
G.add(LeakyReLU(alpha=0.2))
G.add(BatchNormalization(momentum=0.8))
G.add(Dense(1024))
G.add(LeakyReLU(alpha=0.2))
G.add(BatchNormalization(momentum=0.8))
G.add(Dense((self.width*self.height*self.channel), activation='tanh'))
G.add(Reshape((self.width, self.height, self.channel)))
G.summary()
noise = Input(shape=(self.latent_dim,))
## class for cgan
c = Input(shape=(1, ), dtype='int32')
c_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(c))
model_input = multiply([noise, c_embedding])
output = G(model_input)
return Model([noise, c], output)
input은 latent vector와 임베딩 된 class가 함께 들어가게 된다.
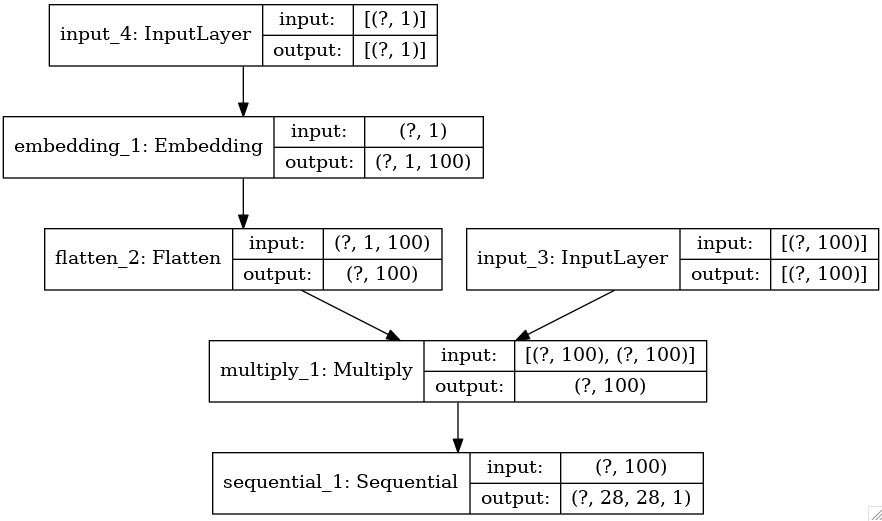
generator의 구조이다.
latent vector는 오른쪽 갈래, class는 왼쪽에 있다. latent vector는 noise를, class는 각 이미지의 구분단위을 의미한다. (MNIST를 예로 들자면 0~9가 class가 될 수 있다.) MNIST에서 3 이미지를 뽑아낸다고 가정한다면, noise와 class 3이 짝을 이뤄 input으로 들어가게 된다. noise는 generator를 통과해 3에 가까운 이미지를 만들도록 학습되는데, 그 옆에는 class 3도 있다.
Discriminator
Discriminaotor를 보면 다음과 같은 형태로 들어간다.
def create_discriminator(self):
D = Sequential()
D.add(Dense(512, input_dim=self.width*self.height*self.channel))
D.add(LeakyReLU(alpha=0.2))
D.add(Dense(512))
D.add(LeakyReLU(alpha=0.2))
D.add(Dropout(0.4))
D.add(Dense(512))
D.add(LeakyReLU(alpha=0.2))
D.add(Dropout(0.4))
D.add(Dense(1, activation='sigmoid'))
D.summary()
img = Input(shape=(self.width, self.height, self.channel))
flat_img = Flatten()(img)
## class for cgan
c = Input(shape=(1, ), dtype='int32')
c_embedding = Flatten()(Embedding(self.num_classes, self.width*self.height*self.channel)(c))
model_input = multiply([flat_img, c_embedding])
output = D(model_input)
return Model([img, c], output)
input은 28x28 이미지를 넓게 편(Flatten) 값들과 임베딩 된 class가 함께 들어가게 된다.
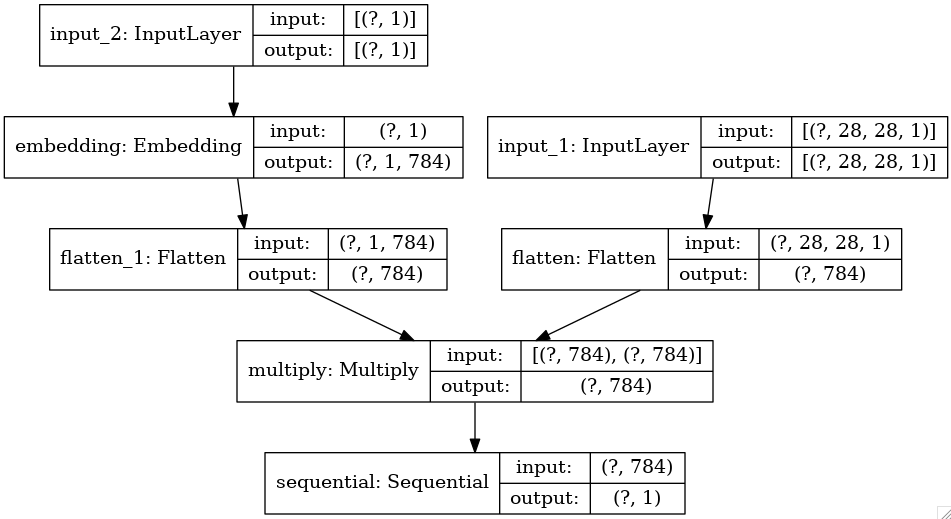
discriminator의 구조이다.
MNIST에서 3 이미지를 뽑아낸다고 가정하면, noise로 만들어진 fake 이미지 + real 이미지와 class 3 이 짝을 이뤄 input으로 들어가게 된다.
real 이미지와 class 3은 짝을 이루고 input으로 들어간다. fake 이미지와 class 3도 짝을 이루고 input으로 들어간다. Discriminator는 특정 요소들을 갖고 있는 것이 3 이라는 것을 진짜로 판별한다. 말이 조금 어렵다. 여태 classification은 특정 요소들을 가지고 있으면 3이라고 판별했지만 특정 요소를 가지고 있는 것이 3이다를 진짜로 판별하는 것은 조금 다르다. 당연하게도 학습이 시작되기 전에는 특정 요소를 가지고 있지 않은데 3이다를 주장하고 있는 generator의 데이터는 가짜로 판별할 것이다.
결과
나머지는 Vanilla GAN과 동일하다. 이제 학습을 오랫동안 시킨 뒤, 이미지를 만들어 낼 때 class 3과 함께 noise를 줘보자.
학습이 끝난 뒤, generatorModel.predict([noise, 3])으로 이미지를 만들어 낼 수 있다.

class 5와 함께 noise를 주면 어떨까? generatorModel.predict([noise, 5])으로 만들 수 있다.

이처럼 원하는 이미지를 class를 통해 만들어 낼 수 있다. noise를 제어하면서 generating을 하고 있기 때문에 꽤나 관심을 많이 받는 모델이다. 이를 계승한 ACGAN, infoGAN 등이 나왔으니 말이다.
전체코드
#!/usr/bin/python
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, Activation, Flatten, Reshape, Embedding
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, UpSampling2D
from tensorflow.keras.layers import LeakyReLU, Dropout, multiply
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.optimizers import Adam, SGD, RMSprop
from tensorflow.keras.utils import plot_model
import keras.backend as K
import ROOT
ROOT.gROOT.SetBatch(True)
import os
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
class CGAN():
def __init__(self):
self.latent_dim = 100
self.num_classes = 10
self.height = 28
self.width = 28
self.channel = 1
# discriminator Nets
self.discriminatorModel = self.create_discriminator()
self.discriminatorModel.compile(loss=['binary_crossentropy'], optimizer=Adam(0.0002, 0.5), metrics=['accuracy'])
# gan Nets
self.generatorModel = self.create_generator()
noise = Input(shape=(self.latent_dim, ))
label = Input(shape=(1, ))
img = self.generatorModel([noise, label])
for layer in self.discriminatorModel.layers:
layer.trainable = False
valid = self.discriminatorModel([img, label])
self.ganModel = Model([noise, label], valid)
self.ganModel.compile(loss=['binary_crossentropy'], optimizer=Adam(0.0002, 0.5), metrics=['accuracy'])
def create_generator(self):
G = Sequential()
G.add(Dense(256, input_dim=self.latent_dim))
G.add(LeakyReLU(alpha=0.2))
G.add(BatchNormalization(momentum=0.8))
G.add(Dense(512))
G.add(LeakyReLU(alpha=0.2))
G.add(BatchNormalization(momentum=0.8))
G.add(Dense(1024))
G.add(LeakyReLU(alpha=0.2))
G.add(BatchNormalization(momentum=0.8))
G.add(Dense((self.width*self.height*self.channel), activation='tanh'))
G.add(Reshape((self.width, self.height, self.channel)))
G.summary()
noise = Input(shape=(self.latent_dim,))
## label for cgan
label = Input(shape=(1, ), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding])
output = G(model_input)
plot_model(Model([noise, label], output), to_file='generator_plot.png', show_shapes=True, show_layer_names=True, expand_nested=False)
return Model([noise, label], output)
def create_discriminator(self):
D = Sequential()
D.add(Dense(512, input_dim=self.width*self.height*self.channel))
D.add(LeakyReLU(alpha=0.2))
D.add(Dense(512))
D.add(LeakyReLU(alpha=0.2))
D.add(Dropout(0.4))
D.add(Dense(512))
D.add(LeakyReLU(alpha=0.2))
D.add(Dropout(0.4))
D.add(Dense(1, activation='sigmoid'))
D.summary()
img = Input(shape=(self.width, self.height, self.channel))
flat_img = Flatten()(img)
## label for cgan
label = Input(shape=(1, ), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.width*self.height*self.channel)(label))
model_input = multiply([flat_img, label_embedding])
output = D(model_input)
plot_model(Model([img, label], output), to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True, expand_nested=False)
return Model([img, label], output)
def train(self, epochs, batch_size, sample_interval):
(X_train, y_train), (_, _) = mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5)/ 127.5
X_train = np.expand_dims(X_train, axis=3)
y_train = y_train.reshape(-1, 1)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs, labels = X_train[idx], y_train[idx]
noise = np.random.normal(0, 1, (batch_size, 100))
gen_img = self.generatorModel.predict([noise, labels])
# Training discriminator Nets
d_loss_real = self.discriminatorModel.train_on_batch([imgs, labels], valid)
d_loss_fake = self.discriminatorModel.train_on_batch([gen_img, labels], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
sampled_labels = np.random.randint(0, 10, batch_size).reshape(-1, 1)
# Training gan Nets
g_loss = self.ganModel.train_on_batch([noise, sampled_labels], valid)
if epoch % sample_interval == 0:
print("%d epochs => D loss: %f, G loss: %f" % (epoch, d_loss[0], g_loss[0]))
if epoch % sample_interval == 0:
self.sample_images(epoch)
def sample_images(self, epoch):
r, c = 2, 5
noise = np.random.normal(0, 1, (r*c, 100))
sampled_labels = np.arange(0, 10).reshape(-1, 1)
gen_imgs = self.generatorModel.predict([noise, sampled_labels])
gen_imgs = 0.5*gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
cnt = 3
axs[i, j].imshow(gen_imgs[cnt,:,:,0], cmap='gray')
axs[i, j].set_title("Digit: %d" % sampled_labels[cnt])
axs[i, j].axis('off')
fig.savefig("/home/jsstar522/Project/CMSCaloGAN/DeepShowerSim_CMSSW_10_6_1/src/DeepShowerSim/1-Training/CMSGAN/cmsCalo_images_WGAN/generated_calo%d" % epoch)
plt.close()
if __name__ == '__main__':
cgan = CGAN()
cgan.train(epochs=20000, batch_size=32, sample_interval=100)