머신러닝에서 학습방식에는 크게 3가지로 구분짓는다. 지도학습 (supervised learning), 비지도학습 (unsupervised learning), 강화학습 (reinforcement learning)으로 나누어진다. 최근에는 답이 주어지지 않은 상태에서 학습하는 비지도 학습이 집중적으로 연구되고 있다. 그 이유는 요즘에는 엄청나게 큰 데이터를 다루는데, 그 데이터에 일일이 labeling을 할 수 없기 때문이다. 비지도학습에는 대표적으로 군집화가 있지만 GAN 또한 비지도학습의 대표적인 예라고 할 수 있다.
GAN(Generative Adversarial Network)
GAN의 핵심은 noise로부터 진짜와 비슷한 거짓 이미지를 생성하는 것이다. 조금 더 수학적으로 얘기해보자면 최종 목적은 데이터의 확률분포 근사이다. 예를들어 수많은 사람의 얼굴 이미지 데이터를 가지고 있다면 이 이미지들은 확률분포로 나타날 것이다.
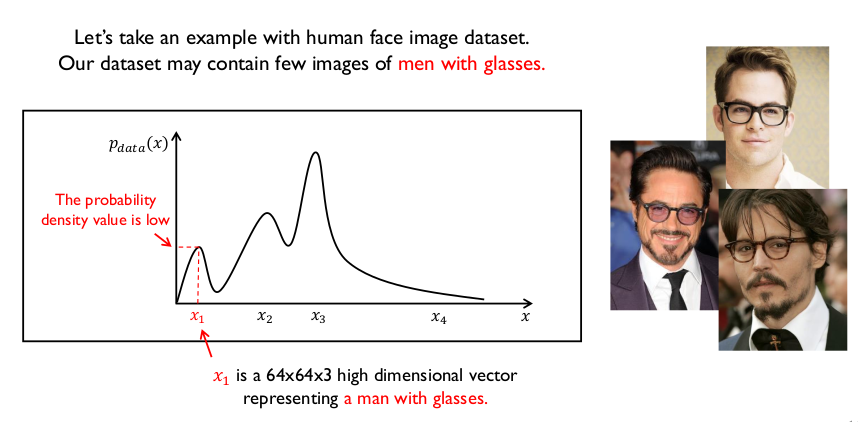
수많은 사람의 얼굴 중 안경을 끼고 있는 사람을 대표하는 벡터가 $x_1$ 이라고 했을 때, 확률분포는 위와 같다.
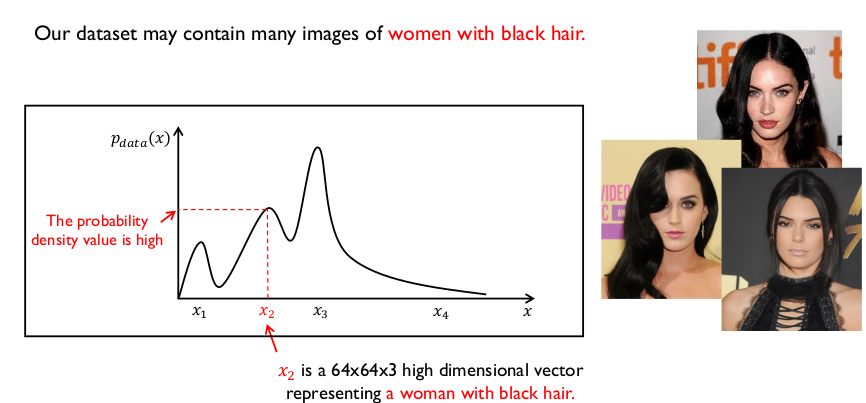
검은색 머리를 하고 있는 여성의 사진 ($x_2$)은 안경을 끼고 있는 남성보다 높은 확률분포를 가진다.
$x$ (이미지)가 있을 때 $P(x)$ 의 확률분포에 대입하면 특정 숫자로 나오게 되는 것이다. $x$ 가 처음에는 noise의 형태로 무작위의 이미지라면 $P(x)$ 와 다른 분포를 그릴 것이다. 원데이터 대한 확률분포와 noise에 대한 확률분포를 근사시키는 것이 Generative model이다. 이 확률분포를 추정하는 것은 데이터 (이미지)에 대한 모든 것을 이해한다는 뜻과 같다.
GAN의 목표는 원데이터에 대한 확률분포를 추정시키는 일이므로 unsupervised learning에 해당한다. 하지만 추정시키는 일에서 멈추는 것이 아니라 그 분포를 직접 만들어 내는 일을 하고 있으므로 군집화와 같은 unsupervised learning과 차이점이 있다.
Discriminator 와 Generator
이 작업을 수행하기 위해서 Discriminator와 Generator 라는 두가지 네트워크가 상호작용을 하면서 학습되는데, 적대적 관계를 형성하고 있기 때문에 adversarial이라는 단어가 붙었다. 이 두 네트워크는 적대적인 관계를 가지고 학습하며 두 네트워크는 최고의 성능을 위해 학습되어야 한다. 최고의 성능을 가진 두 네트워크가 싸우면 어떤일이 벌어질까? 이 현상을 이해하려면 Minimax algorithm 을 보면 된다. Minimax algorithm은 2인 게임(체스, 오목 …)에서 최선의 수를 선택하는 알고리즘이다. Player는 min(상대방)과 max(나)이고 내 턴에서는 이길확률이 높은 수가 선택, 상대방 턴에서는 질확률이 높은 수가 선택된다.
$minmaxV(D, G) = E_{x\text~P_{data}(x)}[logD(x)] + E_{z\text~P_z(z)}[log(1-D(G(z)))]$
여기서 max은 discriminator이고 min은 generator이다. 앞에 있는 term은 실제 데이터 $x$ 를 보고 discriminator가 real이라고 판단할 확률이고 뒤에 있는 term은 가짜 데이터 $G(z)$ 를 보고 discriminator가 fake라고 판단할 확률이다.
먼저 max (discriminator)의 value function을 보면,
$maxV(D) = E_{x\text~P_{data}(x)}[logD(x)] + E_{z\text~P_z(z)}[log(1-D(G(z)))]$
$D(x)$ 는 real term (실제 이미지)이므로 label이 1일 때, 이 term은 0이 된다. 그리고 $D(G(z))$ 는 fake term (가짜 이미지)이므로 label이 0일 때, 이 term 또한 0이다. max는 이 value를 maximize하는 것이 목표다.
min (generator)의 value function을 보면, $G$ 에 관한 식이므로 다음과 같다.
$minV(G) = E_{z\text~P_z(z)}[log(1-D(G(z)))]$
Discriminator
Discriminator는 주어진 사진이 원데이터에 대한 확률분포 $P(x)$ 에 해당하는 데이터인지 구별한다. 쉽게말해, 진짜 이미지인지 가짜 이미지인지 판별한다.
Generator
VAE와 다른점?
L1 Norm
MSE 최소값 평균
Latent Space
더 작은 단위의 차원에서의 확률분포 추정이 가능할까?