youtubeAPI을 사용해서 댓글 추출하기 (2편)
저번 포스팅에서는 API 프로젝트를 생성하고 OAuth 2.0을 만드는 방법을 알아봤다. 이번에는 API KEY 을 발급하고 실제로 youtubeAPI 요청을 보내고 return 값을 받는 방법을 알아보자.
API KEY
API KEY을 만드는 것은 굉장히 간단하다.
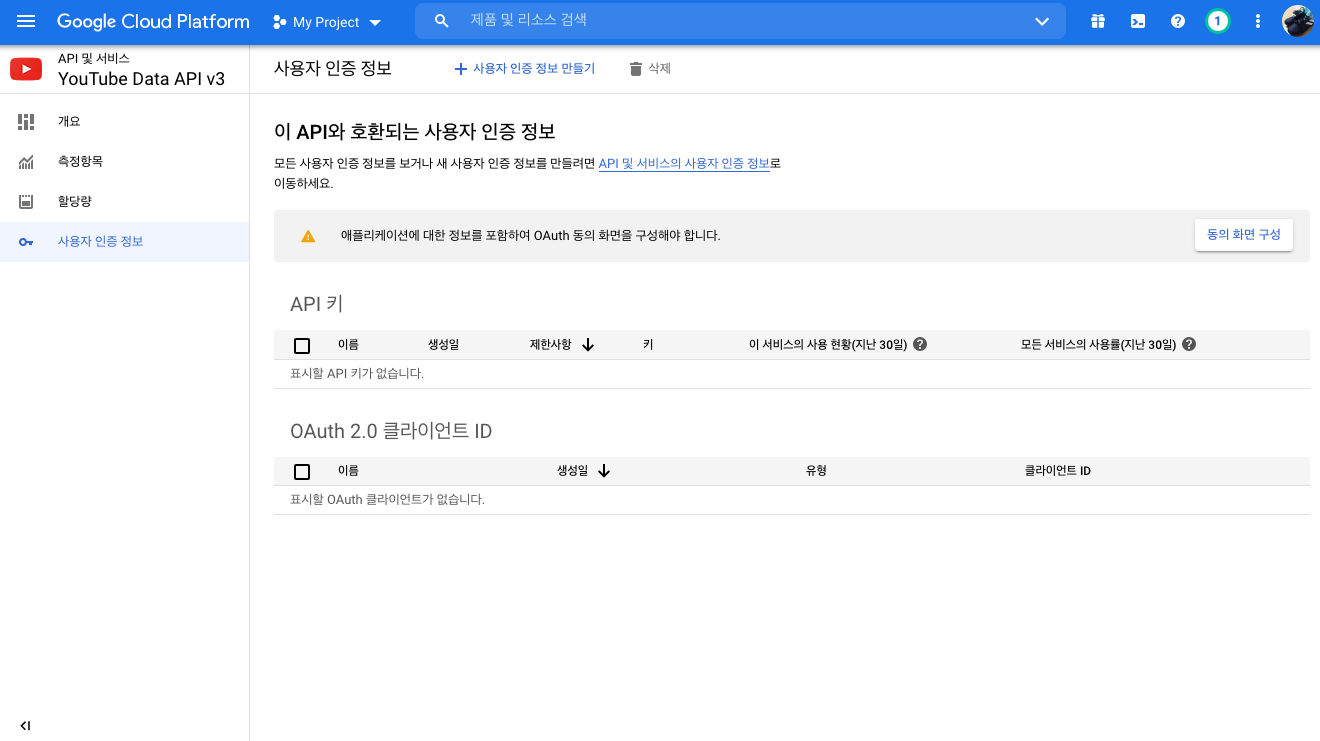
이 화면에서 사용자 인증 정보 만들기 에서 API 키 을 눌르면 바로 발급된다.
요청확인
이제 본격적으로 python 코드를 통해 youtube API 요청을 보내보고 return 값을 받는 방법을 알아보자. 먼저 video 을 성공적으로 불러오면 API은 snippet에 다양한 정보를 담아서 return 해준다. 그 중에 page token 이라는 정보가 담겨있는데, 이 값을 이용하여 검색어를 입력한 이후, 불러오는 첫번째 페이지에 있는 비디오 뿐만 아니라 다음 페이지에 있는 비디오도 계속 가져올 수 있도록 재귀함수를 통하여 구현했다.
# searchAPI.py
#!/usr/bin/python
from googleapiclient.discovery import build
DEVELOPER_KEY = #<Put your API Key>#
YOUTUBE_API_SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
videos = []
def youtube_search(page_token, resultSize, keyword):
youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION,
developerKey=DEVELOPER_KEY)
# Call the search.list method to retrieve results matching the specified
# query term.
search_response = youtube.search().list(
part='snippet',
q=keyword,
maxResults=50,
pageToken=page_token,
# order=options.order,
).execute()
for search_result in search_response.get('items', []):
if search_result['id']['kind'] == 'youtube#video':
videos.append(search_result)
## 원하는 비디오 리스트 개수만큼 나오면 중지
if len(videos) == resultSize:
return videos
## 비디오 리스트 다음페이지가 없을 때까지 재귀호출
if "nextPageToken" in search_response:
print(search_response["nextPageToken"])
youtube_search(search_response["nextPageToken"], resultSize)
return videos
if __name__ == "__main__":
youtube_search(None)
일단 page token을 위해 재귀로 코드를 작성했다는 부분을 제외하고 테스트를 해보자. 위 코드에서 googleapiclient 라는 라이브러리에서 제공하는 모듈을 통해 검색과 같은 요청을 처리할 수 있다. 그리고 5번째줄에 있는 DEVELOPER_KEY 부분에는 앞서 발급했던 API KEY의 번호를 대입시키면 된다. if __name__ == "__main__": 부분 이후에 youtube_search(None) 부분을 youtube_search(None, 1, '유튜브') 라고 바꾸고 바로 밑에 print(youtube_search(None, 1, '유튜브')) 을 추가하고, 실행해보자. 이 요청은 유튜브 라는 검색어와 함께 가장 위에 있는 1페이지의 비디오 정보를 가져오는 것이다.
[{'kind': 'youtube#searchResult', 'etag': 'nR3w5Lp1pxrmAvC-7DX2glzMhi0', 'id': {'kind': 'youtube#video', 'videoId': 'FzG4uDgje3M'}, 'snippet': {'publishedAt': '2018-04-05T19:51:33Z', 'channelId': 'UC4rasfm9J-X4jNl9SvXp8xA', 'title': 'El Chombo - Dame Tu Cosita feat. Cutty Ranks (Official Video) [Ultra Music]', 'description': 'Check out the new "Dame Tu Cosita"! https://youtu.be/FMN3AtsXqA0 El Chombo - Dame Tu Cosita feat. Cutty Ranks El Chombo - Dame Tu Cosita feat.', 'thumbnails': {'default': {'url': 'https://i.ytimg.com/vi/FzG4uDgje3M/default.jpg', 'width': 120, 'height': 90}, 'medium': {'url': 'https://i.ytimg.com/vi/FzG4uDgje3M/mqdefault.jpg', 'width': 320, 'height': 180}, 'high': {'url': 'https://i.ytimg.com/vi/FzG4uDgje3M/hqdefault.jpg', 'width': 480, 'height': 360}}, 'channelTitle': 'Ultra Music', 'liveBroadcastContent': 'none', 'publishTime': '2018-04-05T19:51:33Z'}}]
비디오 뿐만 아니라 썸네일, videoId도 가져오는 것을 확인할 수 있다.
댓글 추출하기
이와 같은 방식으로 댓글 요청을 보내면 된다.
# commentAPI.py
# -*- coding: utf-8 -*-
#!/usr/bin/python
import httplib2
import os
import sys
from apiclient.discovery import build_from_document
from apiclient.errors import HttpError
from oauth2client.client import flow_from_clientsecrets
from oauth2client.file import Storage
from oauth2client.tools import argparser, run_flow
CLIENT_SECRETS_FILE = "client_secrets.json"
YOUTUBE_READ_WRITE_SSL_SCOPE = "https://www.googleapis.com/auth/youtube.force-ssl"
YOUTUBE_API_SERVICE_NAME = "youtube"
YOUTUBE_API_VERSION = "v3"
# # if missing client secrets file.
MISSING_CLIENT_SECRETS_MESSAGE = """
WARNING: Please configure OAuth 2.0
To make this sample run you will need to populate the client_secrets.json file
found at:
%s
with information from the APIs Console
https://console.developers.google.com
For more information about the client_secrets.json file format, please visit:
https://developers.google.com/api-client-library/python/guide/aaa_client_secrets
""" % os.path.abspath(os.path.join(os.path.dirname(__file__),
CLIENT_SECRETS_FILE))
# # client key와 discoverydocument.json 파일 읽어옴
# # discoverydocument.json이 있어야 commentThreads() 메서드를 사용할 수 있다.
def get_authenticated_service(args):
flow = flow_from_clientsecrets(CLIENT_SECRETS_FILE, scope=YOUTUBE_READ_WRITE_SSL_SCOPE,
message=MISSING_CLIENT_SECRETS_MESSAGE)
storage = Storage("%s-oauth2.json" % sys.argv[0])
credentials = storage.get()
if credentials is None or credentials.invalid:
credentials = run_flow(flow, storage, args)
with open("youtube-v3-discoverydocument.json", "r") as f:
doc = f.read()
return build_from_document(doc, http=credentials.authorize(httplib2.Http()))
def get_comments(youtube, video_id, page_token):
results = youtube.commentThreads().list(
part="snippet",
maxResults=100,
videoId=video_id,
pageToken=page_token,
textFormat="plainText"
).execute()
return results
## "최상위 댓글"의 전체 payload를 get_comments로 가져왔으므로 속성별로 나누는 메서드
## 댓글 개수 print(num)
num = 0
def load_comments(match):
# global num
for item in match["items"]:
## 유형
type = "topLevelComment"
## 최상위 댓글
commentDisplay = item["snippet"]["topLevelComment"]["snippet"]["textDisplay"]
## 부모댓글 = 없음
parentId = None
## 최상위 댓글 id
id = item["snippet"]["topLevelComment"]["id"]
## 최상위 댓글 작성자
commentAuthor = item["snippet"]["topLevelComment"]["snippet"]["authorDisplayName"]
commentAuthorId = item["snippet"]["topLevelComment"]["snippet"]["authorChannelId"]["value"]
## 작성날짜
commentDate = item["snippet"]["topLevelComment"]["snippet"]["publishedAt"]
## 좋아요
commentLikeCount = item["snippet"]["topLevelComment"]["snippet"]["likeCount"]
## db 추가
# comments.add_comments(type, id, parentId, commentDisplay, commentAuthor, commentAuthorId, commentDate, commentLikeCount)
print (commentDisplay)
25번째 줄을 보면 CLIENT_SECRETS_FILE = "client_secrets.json" 가 있는데, 이는 OAuth 2.0 내용이 들어간 파일을 의미한다. 이 파일은 저번시간에 발급했던 OAuth 2.0 의 파일버전이다.
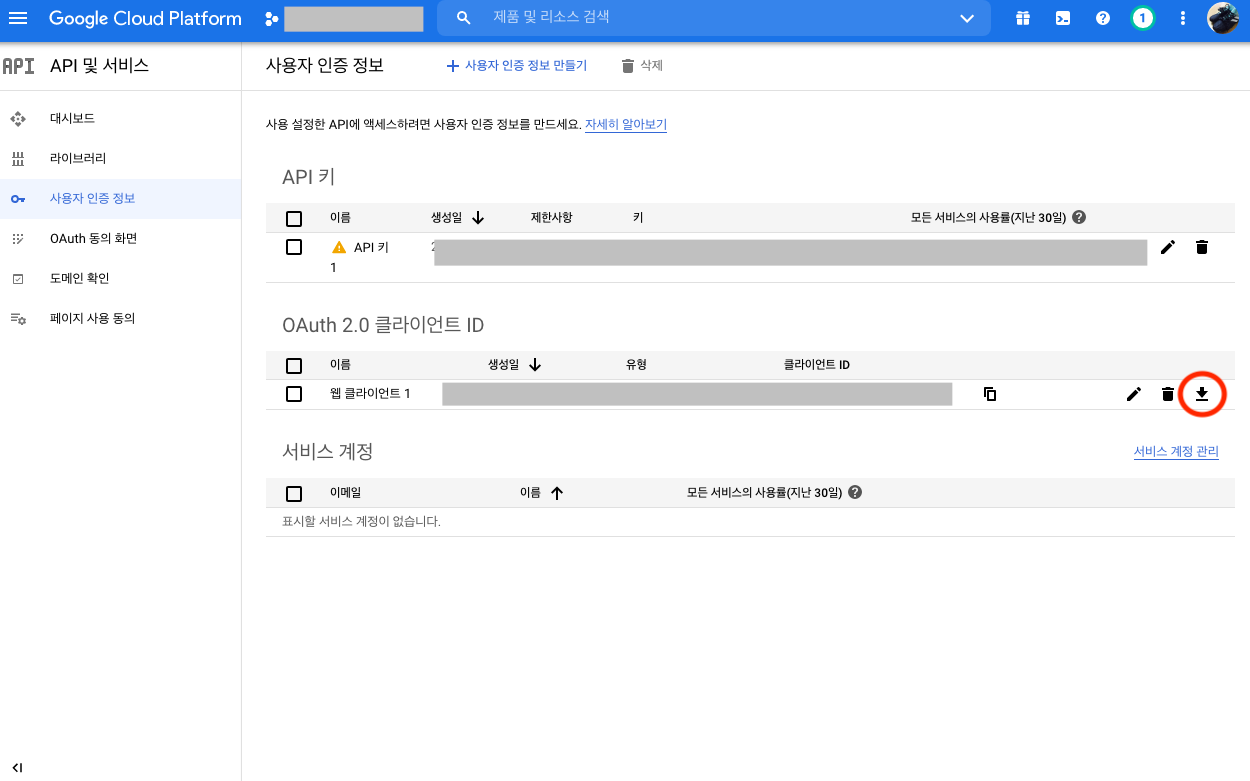
위의 버튼을 눌러서 다운받고 파일이름을 CLIENT_SECRETS_FILE= 에 넣어주면 된다.
그리고 56번째 줄을 보면 with open("youtube-v3-discoverydocument.json", "r") 에 다음과 같은 파일이 필요한데, 이는 youtube 요청 (search, get comment)와 같은 메서드를 불러올 수 있도록 돕는 정보가 들어있는 파일이다.
https://www.googleapis.com/discovery/v1/apis/youtube/v3/rest
이 곳에 내용이 저장되어 있으니 내용을 복사하거나 파일로 받아야 한다.
이제 get_comments 메서드를 사용하여 댓글부분을 뽑아보자.
# commentAPI.py (계속)
## vedeoid를 인자로 받아서 댓글 추출
def get_allComments(videoid):
## args에 video ID 추가
args.videoid = videoid
global youtube
youtube = get_authenticated_service(args)
try:
match = get_comments(youtube, args.videoid, None)
load_comments(match)
except HttpError as e:
print ("An HTTP error %d occurred:\n%s" % (e.resp.status, e.content))
else:
print ("################### All Comments of One Video ###################")
if __name__ == "__main__":
import searchAPI
## videoid를 인자로 받아서 args 새롭게 생성
argparser.add_argument("--keyword",
help="Required; KEYWORD for search videos")
argparser.add_argument("--resultSize", type = int,
help="Required; Number of searched video lists")
argparser.add_argument("--videoid")
args = argparser.parse_args()
print(args)
if not args.keyword:
exit("Please specify keword for search videos using the --keyword='<parameter>'.")
if not args.resultSize:
exit("Please specify number of searched video lists using the --resultSize='<parameter>'.")
num = 0
for video in searchAPI.youtube_search(None, args.resultSize, args.word):
num += 1
print(num)
## 댓글 추출 시작
get_allComments(video['id']['videoId'])
마지막 부분인 for 문은 앞서 작성했던 searchAPI.py 파일을 불러온다. 이 파일에선 videoId을 반환하도록 되어 있다. 이 videoId 은 get_allComments 함수에 전달되어 해당 비디오의 댓글을 불러오도록 요청을 보낸다.
#############################
Video Title: Spicy rice cake (Tteokbokki: 떡볶이)
Video Author: Maangchi
createdAt: 2013-01-31T02:43:31Z
channelId: UC8gFadPgK2r1ndqLI04Xvvw
#############################
Had this for the first time yesteday and its honestly one of the best dish I've ever had
Thanks.... this is so easy to make. My daughter loves to eat this and now I can cook for her.
Can i add rice to the ddeokbokki ????
I love her so muchh
would chicken stock work aswell??
Yes, delicious broth makes delicious tteokbokki. Chicken or beef stock will work well even though I prefer anchovy stock.
I have a question how to make a vegetarian dabke.?
i love ddeokbokki!! can't wait to make this recipe someday 🤩
man only if i was good at cooking i can only make noodles
Is it ok to use seaweed instead of kelp if i dont find it here in our place?
Manggchi if we don't have kelp can we just use fish sauce? Or just water?
Maangchi thank you maangchi
I use vegetable stock, seems like the chili paste gives it most of its taste, and if you don’t mind not having the fishy taste. All in all great snack.
:D
Kelp can be skipped but use can use only dried anchovies. Fish sauce is very salty, so it won't work.
I am gonna make this tomorrow. Thank you!
omg we love you recipe >>>thank you so much!!!!!!
Thank you for sharing your recipe. It looks so great! I am running to the kitchen to make it now. Oops, I think I need to go to the Korean grocery first.
O nasıl şeker aga
Are they halal??
What do you want? Koreans don't eat halal. Tteokbokki is KOREAN food.
Can I use purple onion?
thank u so much
...생략...
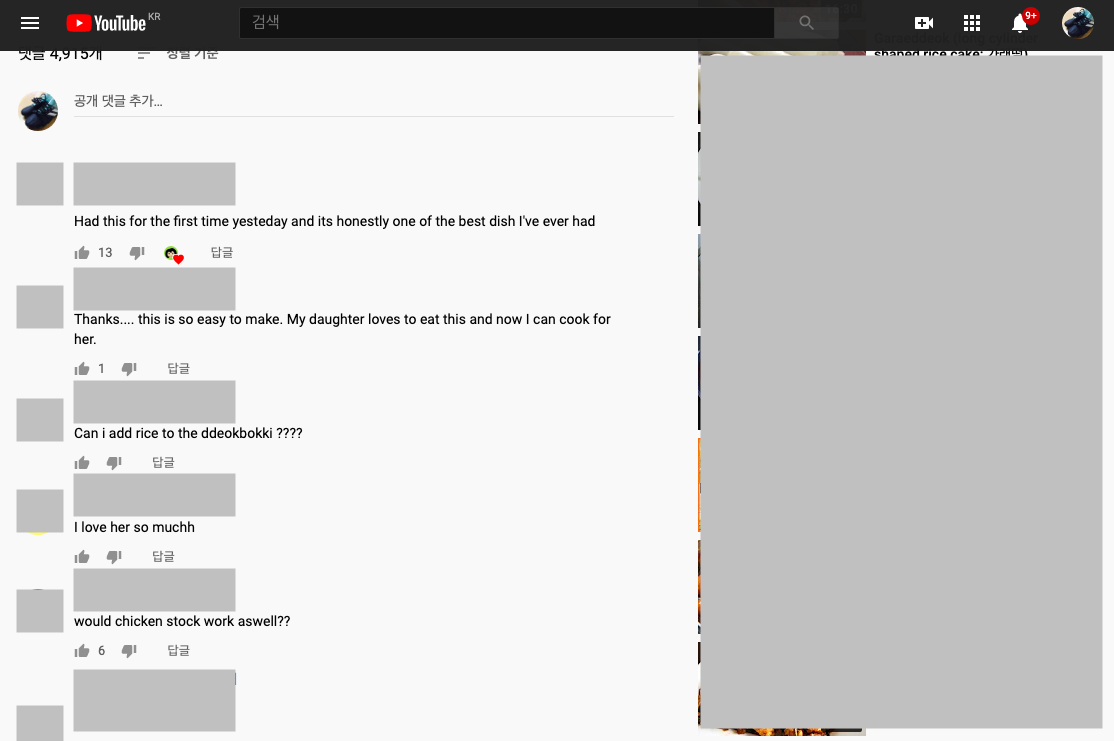
실제 비디오에 가서 댓글을 확인해보면 내용이 잘 나왔다는 것을 확인할 수 있다.
Full Code
https://github.com/jsstar522/AI-lab/tree/master/youtubeAPI